The other day, I had the genius idea of creating fanfictions using AI. I had a few anime series in mind, but it didn't really matter which one. It's a "Just for fun"* idea... For that, I needed a lot of data on the characters, setting, and an AI model good at creative writing with a long context length.
For the data part, I decided to collect data from Wikia/Fandom.com pages, and since taking the whole page will waste a lot of AI Tokens, I wanted a fast way to crawl the website and only take the data I wanted.
Method:
Ideally, I want to be able to create a text file containing only the relevant data for the fanfiction I'm creating... So, here's the method I arrived at:
- Crawl the whole Wiki for the series I'm looking at. (Example: Dragon Ball)
- Convert the crawled pages into Markdown Files suitable for [Obsidian] Notes App
- Use Obsidian's Embeddings Plugins, and ChatGPT Plugin, to create an even more focused .txt file containing only the info I need to pass to the AI
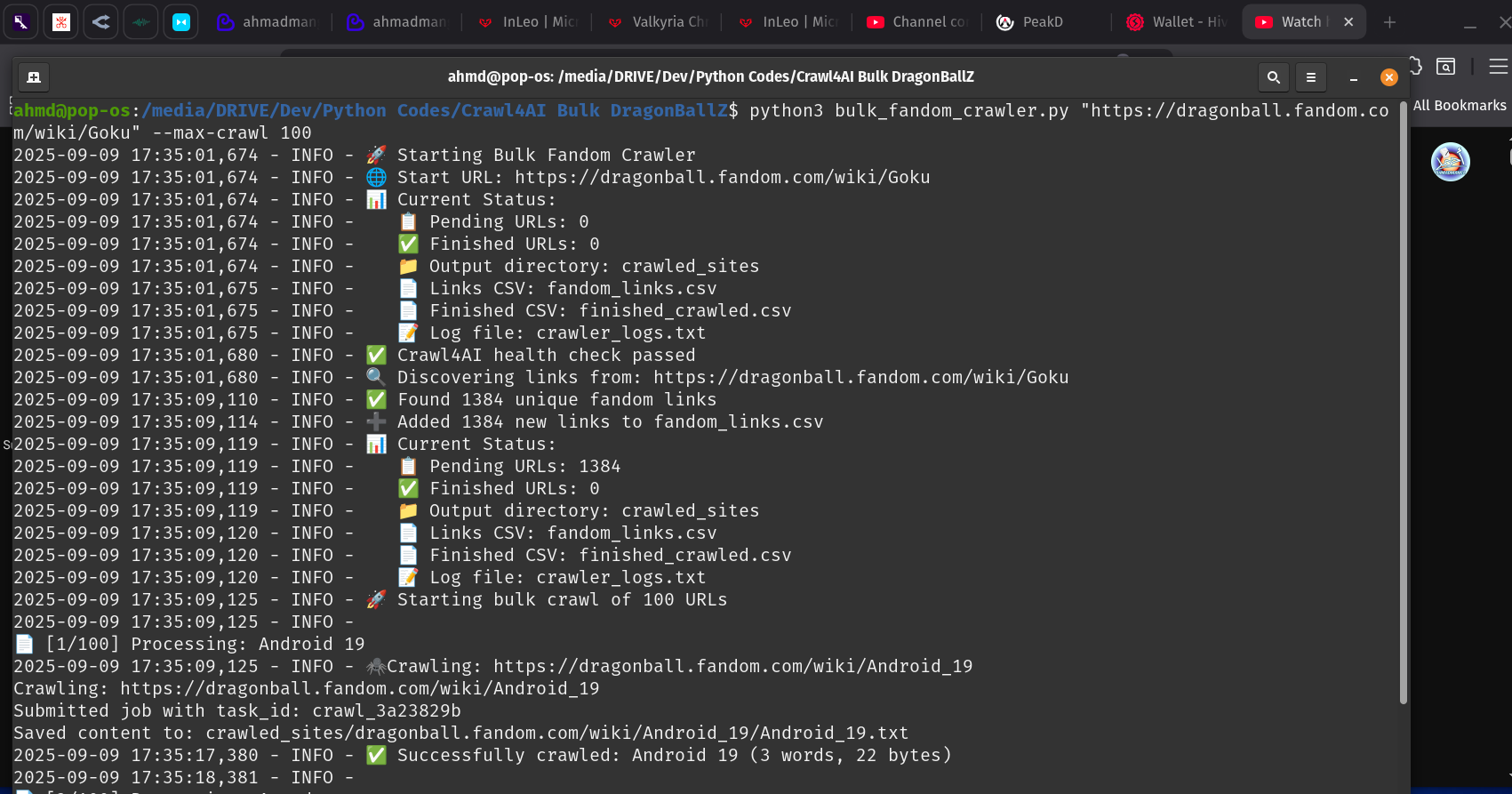
For the crawling part, I used Crawl4AI's Docker App, which needs a Pyhton code to call it. I used AI to create a code suitable for crawling Fandom.com websites and removing redundant parts of the page. The result are a batch of markdown files that I put in my Obsidian vault for further refining...
Pre-requites
- Crawl4AI Docker Version: https://github.com/unclecode/crawl4ai
- Obsidian: https://obsidian.md/
- Obsidian Smart Connections Plugin: https://github.com/brianpetro/obsidian-smart-connections
The Code
So, here's my current code. It's working but kind of clunky, and since I vibe-coded it using AI, I'm not sure how all of it works, (I only understand the basics,) so further editing would be a nightmare...
Still, I decided to share it, just in case anyone is interested:
Disclaimer: Code created using Qwen3-235B model over 1 hour of conversation. The result are the two files below:
bulk_fandom_crawler.py:
The code below is called via terminal: python3 bulk_fandom_crawler.py WEBSITEURL --max-crawl PAGESCOUNT
import csv
import os
import re
import requests
from urllib.parse import urlparse, urljoin
from bs4 import BeautifulSoup
from crawl_to_mkdn import Crawl4AiCrawler
import time
import logging
from typing import Set, List, Tuple
class BulkFandomCrawler:
def __init__(self, base_url: str = "http://localhost:11235"):
self.crawler = Crawl4AiCrawler(base_url)
self.links_csv = "fandom_links.csv"
self.finished_csv = "finished_crawled.csv"
self.output_root = "crawled_sites"
self.log_file = "crawler_logs.txt"
# Initialize logging
self._setup_logging()
# Initialize CSV files
self._init_csv_files()
def _setup_logging(self):
"""Setup logging to file and console."""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(self.log_file, encoding='utf-8'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def _init_csv_files(self):
"""Initialize CSV files with headers if they don't exist."""
# Initialize links CSV
if not os.path.exists(self.links_csv):
with open(self.links_csv, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['URL', 'Topic_Title', 'Subdomain', 'Status'])
self.logger.info(f"📄 Created new links CSV: {self.links_csv}")
# Initialize finished CSV
if not os.path.exists(self.finished_csv):
with open(self.finished_csv, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['URL', 'Topic_Title', 'Subdomain', 'Crawl_Date', 'Success', 'Word_Count', 'File_Size'])
self.logger.info(f"📄 Created new finished CSV: {self.finished_csv}")
def _get_finished_urls(self) -> Set[str]:
"""Get set of already crawled URLs from finished CSV."""
finished_urls = set()
if os.path.exists(self.finished_csv):
with open(self.finished_csv, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
finished_urls.add(row['URL'])
return finished_urls
def _extract_title_from_url(self, url: str) -> str:
"""Extract topic title from fandom URL."""
parsed = urlparse(url)
path_parts = parsed.path.strip('/').split('/')
if 'wiki' in path_parts:
wiki_index = path_parts.index('wiki')
if wiki_index + 1 < len(path_parts):
title = path_parts[wiki_index + 1]
# Replace underscores with spaces and decode URL encoding
title = title.replace('_', ' ')
return title
return "Unknown"
def _get_subdomain(self, url: str) -> str:
"""Extract subdomain from fandom URL."""
parsed = urlparse(url)
domain_parts = parsed.netloc.split('.')
if len(domain_parts) >= 3 and 'fandom.com' in parsed.netloc:
return domain_parts[0]
return "unknown"
def discover_links(self, start_url: str) -> List[Tuple[str, str, str]]:
"""
Discover fandom links from a starting URL.
Returns list of (url, title, subdomain) tuples.
"""
self.logger.info(f"🔍 Discovering links from: {start_url}")
try:
# Use requests to get the page content for link discovery
response = requests.get(start_url, timeout=30)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
# Extract subdomain from start URL
start_subdomain = self._get_subdomain(start_url)
# Find all links
links = []
for link in soup.find_all('a', href=True):
href = link['href']
# Convert relative URLs to absolute
if href.startswith('/'):
href = urljoin(start_url, href)
# Check if it's a fandom wiki link from same subdomain
if self._is_valid_fandom_link(href, start_subdomain):
title = self._extract_title_from_url(href)
subdomain = self._get_subdomain(href)
links.append((href, title, subdomain))
# Remove duplicates
unique_links = list(set(links))
self.logger.info(f"✅ Found {len(unique_links)} unique fandom links")
return unique_links
except Exception as e:
self.logger.error(f"❌ Error discovering links from {start_url}: {str(e)}")
return []
def _is_valid_fandom_link(self, url: str, target_subdomain: str) -> bool:
"""Check if URL is a valid fandom wiki link from the target subdomain."""
try:
parsed = urlparse(url)
# Must be fandom.com domain
if 'fandom.com' not in parsed.netloc:
return False
# Must be from same subdomain
if self._get_subdomain(url) != target_subdomain:
return False
# Must be a wiki page
if '/wiki/' not in parsed.path:
return False
# Exclude certain pages
excluded_patterns = [
'Special:', 'File:', 'Category:', 'Template:', 'User:', 'Talk:',
'action=', 'oldid=', '#', '?'
]
for pattern in excluded_patterns:
if pattern in url:
return False
return True
except Exception:
return False
def add_links_to_csv(self, links: List[Tuple[str, str, str]]):
"""Add discovered links to the main links CSV."""
existing_urls = set()
# Read existing URLs
if os.path.exists(self.links_csv):
with open(self.links_csv, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
existing_urls.add(row['URL'])
# Add new links
new_links = 0
with open(self.links_csv, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for url, title, subdomain in links:
if url not in existing_urls:
writer.writerow([url, title, subdomain, 'pending'])
new_links += 1
self.logger.info(f"➕ Added {new_links} new links to {self.links_csv}")
def get_pending_urls(self) -> List[Tuple[str, str, str]]:
"""Get URLs that haven't been crawled yet."""
finished_urls = self._get_finished_urls()
pending_urls = []
if os.path.exists(self.links_csv):
with open(self.links_csv, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
if row['URL'] not in finished_urls and row['Status'] == 'pending':
pending_urls.append((row['URL'], row['Topic_Title'], row['Subdomain']))
return pending_urls
def crawl_url(self, url: str, title: str, subdomain: str) -> bool:
"""Crawl a single URL and record the result."""
try:
self.logger.info(f"🕷️ Crawling: {url}")
self.crawler.crawl_and_save(url, self.output_root)
# Calculate stats for the crawled content
word_count, file_size = self._get_content_stats(url)
# Record success in finished CSV
with open(self.finished_csv, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([url, title, subdomain, time.strftime('%Y-%m-%d %H:%M:%S'), 'True', word_count, file_size])
self.logger.info(f"✅ Successfully crawled: {title} ({word_count} words, {file_size} bytes)")
return True
except Exception as e:
self.logger.error(f"❌ Failed to crawl {url}: {str(e)}")
# Record failure in finished CSV
with open(self.finished_csv, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([url, title, subdomain, time.strftime('%Y-%m-%d %H:%M:%S'), 'False', 0, 0])
return False
def _get_content_stats(self, url: str) -> Tuple[int, int]:
"""Get word count and file size for crawled content."""
try:
# Parse URL to find the output file
parsed = urlparse(url)
site_dir = parsed.netloc
path = parsed.path.strip("/")
full_path_dir = os.path.join(self.output_root, site_dir, path)
filename = "index.txt" if not path else f"{path.split('/')[-1]}.txt"
output_file = os.path.join(full_path_dir, filename)
if os.path.exists(output_file):
file_size = os.path.getsize(output_file)
with open(output_file, 'r', encoding='utf-8') as f:
content = f.read()
word_count = len(content.split())
return word_count, file_size
except Exception as e:
self.logger.warning(f"⚠️ Could not calculate stats for {url}: {str(e)}")
return 0, 0
def bulk_crawl(self, max_urls: int = None, delay: float = 1.0):
"""Perform bulk crawling of pending URLs."""
pending_urls = self.get_pending_urls()
if not pending_urls:
self.logger.info("📭 No pending URLs to crawl")
return
if max_urls:
pending_urls = pending_urls[:max_urls]
self.logger.info(f"🚀 Starting bulk crawl of {len(pending_urls)} URLs")
success_count = 0
total_words = 0
total_size = 0
for i, (url, title, subdomain) in enumerate(pending_urls, 1):
self.logger.info(f"\n📄 [{i}/{len(pending_urls)}] Processing: {title}")
if self.crawl_url(url, title, subdomain):
success_count += 1
# Get stats for this crawl
word_count, file_size = self._get_content_stats(url)
total_words += word_count
total_size += file_size
# Add delay between requests
if delay > 0 and i < len(pending_urls):
time.sleep(delay)
self.logger.info(f"\n🎉 Bulk crawl completed!")
self.logger.info(f"📊 Results: {success_count}/{len(pending_urls)} successful")
self.logger.info(f"📝 Total words: {total_words:,}")
self.logger.info(f"💾 Total size: {total_size:,} bytes")
def start_crawling(self, start_url: str, discover_new: bool = True, max_crawl: int = None):
"""Main method to start the crawling process."""
self.logger.info("🚀 Starting Bulk Fandom Crawler")
self.logger.info(f"🌐 Start URL: {start_url}")
# Show current status
self._show_status()
# Validate start URL
if not self._is_valid_fandom_link(start_url, self._get_subdomain(start_url)):
self.logger.error("❌ Invalid fandom URL provided")
return
# Check Crawl4AI health
try:
health = requests.get("http://localhost:11235/health", timeout=10)
if health.status_code != 200:
self.logger.error("❌ Crawl4AI service not healthy")
return
self.logger.info("✅ Crawl4AI health check passed")
except requests.exceptions.RequestException:
self.logger.error("❌ Could not connect to Crawl4AI. Please start the Docker container:")
self.logger.error(" docker run -p 11235:11235 ghcr.io/unclecode/crawl4ai:latest")
return
# Discover new links if requested
if discover_new:
links = self.discover_links(start_url)
if links:
self.add_links_to_csv(links)
# Show updated status
self._show_status()
# Start bulk crawling
self.bulk_crawl(max_urls=max_crawl)
def _show_status(self):
"""Display current crawler status."""
pending_count = len(self.get_pending_urls())
finished_count = len(self._get_finished_urls())
self.logger.info("📊 Current Status:")
self.logger.info(f" 📋 Pending URLs: {pending_count}")
self.logger.info(f" ✅ Finished URLs: {finished_count}")
self.logger.info(f" 📁 Output directory: {self.output_root}")
self.logger.info(f" 📄 Links CSV: {self.links_csv}")
self.logger.info(f" 📄 Finished CSV: {self.finished_csv}")
self.logger.info(f" 📝 Log file: {self.log_file}")
def main():
import sys
if len(sys.argv) < 2:
print("Usage: python bulk_fandom_crawler.py [--no-discover] [--max-crawl N]")
print("Example: python bulk_fandom_crawler.py https://mushokutensei.fandom.com/wiki/Roxy_Migurdia")
print("Options:")
print(" --no-discover: Skip link discovery, only crawl existing pending URLs")
print(" --max-crawl N: Limit crawling to N URLs")
sys.exit(1)
start_url = sys.argv[1]
discover_new = '--no-discover' not in sys.argv
max_crawl = None
# Parse max-crawl option
if '--max-crawl' in sys.argv:
try:
max_idx = sys.argv.index('--max-crawl')
if max_idx + 1 < len(sys.argv):
max_crawl = int(sys.argv[max_idx + 1])
except (ValueError, IndexError):
print("❌ Invalid --max-crawl value")
sys.exit(1)
# Start crawling
crawler = BulkFandomCrawler()
crawler.start_crawling(start_url, discover_new=discover_new, max_crawl=max_crawl)
if __name__ == "__main__":
main()
crawl2obsidian.py:
```
!/usr/bin/env python3
""" Convert crawled Fandom pages to clean Obsidian markdown vault. Keeps images but strips all URL links while preserving text content. """
import os import re from pathlib import Path
def clean_fandom_content(content): """Clean fandom content by removing links but keeping images and text."""
# Keep images but remove their URLs - convert  to ![alt]
content = re.sub(r'!\[([^\]]*)\]\([^)]+\)', r'![\1]', content)
# Remove fandom links but keep the display text
# Pattern: [text](https://mushokutensei.fandom.com/wiki/Page "Page")
content = re.sub(r'\[([^\]]+)\]\(https://[^.]+\.fandom\.com/[^)]+\)', r'\1', content)
# Remove internal navigation links like [1 Receptionist](url#section) but keep text
content = re.sub(r'\[[\d\.]+ ([^\]]+)\]\([^)]+#[^)]+\)', r'\1', content)
# Remove edit links [[](auth.fandom.com...)]
content = re.sub(r'\[\[\]\([^)]+\)\]', '', content)
# Remove citation links like [[1]](url) but keep the number
content = re.sub(r'\[\[(\d+)\]\]\([^)]+\)', r'[\1]', content)
# Remove "Jump up" reference links
content = re.sub(r'\[↑\]\([^)]+\s+"[^"]*"\)', '', content)
content = re.sub(r'↑ \[Jump up to: [^\]]+\]', '', content)
# Remove remaining markdown links but keep text
content = re.sub(r'\[([^\]]+)\]\([^)]+\)', r'\1', content)
# Remove HTML-like tags
content = re.sub(r'<[^>]+>', '', content)
# Remove table separators
content = re.sub(r'^---\s*$', '', content, flags=re.MULTILINE)
# Remove "Sign in to edit" text
content = re.sub(r'"Sign in to edit"', '', content)
# Remove lines that are just numbers (like "1/2", "1/3")
content = re.sub(r'^\d+/\d+\s*$', '', content, flags=re.MULTILINE)
# Remove "Voiced by:" lines with complex formatting
content = re.sub(r'Voiced by:.*?(?=\n##|\n\n|\Z)', '', content, flags=re.DOTALL)
# Clean up navigation sections at the end
content = re.sub(r'## Navigation.*?$', '', content, flags=re.DOTALL)
# Remove expand sections
content = re.sub(r'Expand\[.*?\].*?(?=\n##|\n\n|\Z)', '', content, flags=re.DOTALL)
# Clean up multiple empty lines
content = re.sub(r'\n\s*\n\s*\n+', '\n\n', content)
# Remove empty lines at start and end
content = content.strip()
return content
def is_empty_content(content): """Check if content is empty or only contains '(No content extracted)'.""" cleaned = content.strip() return ( not cleaned or cleaned == "(No content extracted)" or len(cleaned) < 10 # Very short content is likely meaningless )
def remove_empty_directories(directory): """Recursively remove empty directories.""" removed_count = 0
# Walk bottom-up to remove empty directories
for root, dirs, files in os.walk(directory, topdown=False):
for dir_name in dirs:
dir_path = os.path.join(root, dir_name)
try:
# Try to remove if empty
os.rmdir(dir_path)
removed_count += 1
print(f"Removed empty directory: {dir_path}")
except OSError:
# Directory not empty, sk