
Last year, Ecency became one of the most popular platforms for user communication, idea implementation, and fund management.
Today, the web version alone contains over 500K lines of code and more than 5 000 commits. It’s a truly grand project—and it now requires new technologies and mechanisms to stay simple, scalable, configurable, and stable.
Ecency currently relies on 100+ client-side dependencies and 41 development/build/CI/CD dependencies. Given these numbers, we’ve decided to create our own SDK for building scalable applications on top of the Hive and Ecency APIs. Let’s dive in!

Moving to SDK
The basic structure of any web project is: fetch some data, display it, and mutate it. Mutation can happen on the client side or by making a request to the server. In Ecency we use several APIs: the general Hive JSON-RPC API, Ecency’s private API, and external integrations such as CoinGecko, Worldmappin, 3Speak, and Plausible Analytics. Because we work with many different APIs, we chose @tanstack/react-query (hereafter RQ) to manage them all.
RQ provides powerful tools for request management, reduces boilerplate, and acts as a lightweight state manager. RQ isn’t tied to React or Next.js, so it can live outside the main project. Why separate it? To keep ecency-vision focused purely on UI/UX. React shouldn’t worry about heavy state management or complex data streams—it should simply receive data, react to changes, and trigger effects. Another reason: our mobile application. The SDK can be reused there (even if that’s only a future option). And finally: configurability. We want any Ecency instance to be self-hostable—able to disable unneeded features or add custom ones. That’s why we need the SDK now.
Architecture & structure
The SDK consists of two packages: @ecency/sdk and @ecency/wallets. The main SDK handles everything except wallet management, which lives in the wallets package because it has specific dependencies such @okweb3/* and bitcore-lib. Both packages share the same structure: modules that contain queries, mutations, functions, constants, and types.
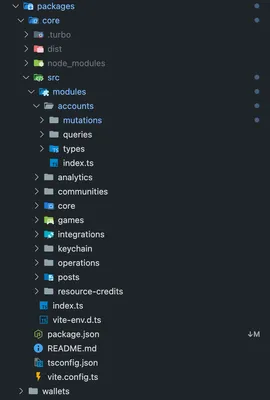
Dependencies
As we move existing logic into the new repository, we also have to move dependencies. NPM’s peerDependency feature isn’t ideal here because most packages may use different patch versions, which would generate a flood of warnings. Instead, we use devDependencies together with Vite. Vite lets us exclude certain dependencies from the build (they’re imported depending on build type). This way, all dependencies ultimately remain in the host project rather than in the SDK.
State management
Of course, the SDK maintains a large state. Since 99 % of our data comes from APIs, we continue to use React Query for state. State is managed via queries, and the SDK exposes flexible queryOptions so we can tweak configurations when needed. For example:
const accountQuery = useQuery({
...getAccountFullQueryOptions(username),
enabled: username === 'dkildar',
select: (data) => data.posting.account_auths
})
Every piece of state can be mutated. Instead of Redux-style mutations, we rely on RQ mutations—promises representing API requests or other actions. We then handle their lifecycle with hooks like onSuccess, onError, and onSettled, and apply optimistic updates when appropriate.
Letter for Hive developers
The SDK can be integrated into any Hive client that uses React Query under the hood. It lets you remove boilerplate code and stop worrying about local state—everything just works automatically. Feel free to open pull requests or suggest improvements.
Source: https://github.com/ecency/sdk
This is the first part of our series on the SDK and configurability. In the next posts we’ll dive deeper into Hive operation specifications, sequential data streaming, and more. See you soon!